
Welcome back, folks! In this series of 3 blog post, we will be discussing pandas which one of my favorite python libraries. We will go through 74 exercises to solidify your skills with pandas and as usual, I will explain the WHY behind every single exercise.
Pandas is a powerful open-source library for data analysis and data manipulation. The library is packed with a ton of feature, well supported and documented by the community. It is built on top of NumPy and integrate well with all the main machine learning libraries like Scikit-learn and Matplotlib.
Pandas already come bundles in the Anaconda distribution. If you don’t have it installed already, please refer to my other blog here to get you started.
These exercises are inspired from this amazing blog post.
Remember there is always different ways we can achieve the same result, so if your code does not look like mine. No worries! if you got the same result, then you are good to go.
Now let’s jump right in into the exercises.
Ex 1: How to import pandas and check the version?
Q: As a warm up, we will import pandas and print it’s version
Solution
import pandas as pd
pd.__version__
'0.23.4'
We import pandas as pd which is the common way to refer to pandas and use the dot notation to print its version.
Ex 2: How to create a series from a list, numpy array and dict?
Q: Create a pandas series from each of the items below: a list, numpy and a dictionary and print the first 5 elements.
import numpy as np
mylist = list('abcedfghijklmnopqrstuvwxyz')
myarr = np.arange(26)
mydict = dict(zip(mylist, myarr))
Desired output
# List
# 0 a
# 1 b
# 2 c
# 3 e
# 4 d
# dtype: object
#
# Array
# 0 0
# 1 1
# 2 2
# 3 3
# 4 4
# dtype: int64
#
# Dictionary
# a 0
# b 1
# c 2
# e 3
# d 4
# dtype: int64
Solution
pd.Series(mylist).head()
0 a
1 b
2 c
3 e
4 d
dtype: object
pd.Series(myarr).head()
0 0
1 1
2 2
3 3
4 4
dtype: int64
pd.Series(mydict).head()
a 0
b 1
c 2
e 3
d 4
dtype: int64
Let’s first explain what is a series in pandas, as I said at the beginning of this post, pandas is a tool for data manipulation and most of the data is in form of tables and tables are comprised of columns. In pandas, the data are represented in a dataframe comprised of columns and rows and the basic data structure of a dataframe is a series comprised of one column and an index column.
Coming back to our exercise, we are casting(changing the datatype) the list, array and the dictionary into a Series comprised of only one column of data and another column of indexes by using the Series method and print only the first 5 elements.
Ex 3: How to convert the index of a series into a column of a dataframe?
Q: Convert the series ser into a dataframe with its index as another column on the dataframe.
mylist = list('abcedfghijklmnopqrstuvwxyz')
myarr = np.arange(26)
mydict = dict(zip(mylist, myarr))
ser = pd.Series(mydict)
Desired output
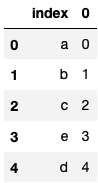
Solution
ser.to_frame().reset_index().head()
| index | 0 | |
|---|---|---|
| 0 | a | 0 |
| 1 | b | 1 |
| 2 | c | 2 |
| 3 | e | 3 |
| 4 | d | 4 |
To convert a series into a dataframe, we use the to_frame method and to change the ser’s index to number, we use the reset_index. We finally print the first 5 elements in the dataframe.
Ex 4: How to combine many series to form a dataframe?
Q: Combine ser1 and ser2 to form a dataframe.
import numpy as np
ser1 = pd.Series(list('abcedfghijklmnopqrstuvwxyz'),name="ser1")
ser2 = pd.Series(np.arange(26),name="ser2")
Desired output
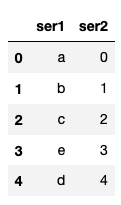
Solution
1st Method
pd.concat([ser1,ser2],axis=1).head()
| ser1 | ser2 | |
|---|---|---|
| 0 | a | 0 |
| 1 | b | 1 |
| 2 | c | 2 |
| 3 | e | 3 |
| 4 | d | 4 |
We can concatenate the two series into on a Dataframe using the concat method and set the axis equal to 1 to concatenate column-wise. We finally print the first 5 elements.
2nd Method
pd.DataFrame({"ser1":ser1,"ser2":ser2}).head()
| ser1 | ser2 | |
|---|---|---|
| 0 | a | 0 |
| 1 | b | 1 |
| 2 | c | 2 |
| 3 | e | 3 |
| 4 | d | 4 |
An alternative way to solve this issue, would be to use DataFrame method and passed in a dictionary where the keys are the column’s names and the value are the series and then print the first 5 elements.
Ex 5: How to assign name to the series’ index?
Q: Give a name to the series ser calling it ‘alphabets’.
ser = pd.Series(list('abcedfghijklmnopqrstuvwxyz'))
Desired output
# a 0
# b 1
# c 2
# e 3
# d 4
# Name: alphabets, dtype: int64
Solution
ser.name = "alphabets"
ser.head()
a 0
b 1
c 2
e 3
d 4
Name: alphabets, dtype: int64
We give a name to a series through the dot operator by calling the name method and assign it the actual name, in this example “alphabets”
Ex 6: How to get the items of series A not present in series B?
Q: From ser1 remove items present in ser2.
ser1 = pd.Series([1, 2, 3, 4, 5])
ser2 = pd.Series([4, 5, 6, 7, 8])
Desired output
# 0 1
# 1 2
# 2 3
# dtype: int64
Solution
ser1[~ser1.isin(ser2)]
0 1
1 2
2 3
dtype: int64
We first find which elements present both in ser1 and ser2 using isin method, a boolean DataFrame is returned where True is the position of elements present in ser1 and ser2 and where False is the position of elements only in ser1.
So to get the elements unique to ser1, we use the ~ to reverse the boolean DataFrame and then use indexing to get the actual value.
Ex 7: How to get the items not common to both series A and series B?
Q: Get all items of ser1 and ser2 not common to both.
ser1 = pd.Series([1, 2, 3, 4, 5])
ser2 = pd.Series([4, 5, 6, 7, 8])
Desired output
# 0 1
# 1 2
# 2 3
# 3 6
# 4 7
# 5 8
# dtype: int64
Solution
1st Method
unique_ser1 = ser1[~ser1.isin(ser2)]
unique_ser2 = ser2[~ser2.isin(ser1)]
We get elements that are not common in both series just like we did in exercise 6
unique_ser1
0 1
1 2
2 3
dtype: int64
unique_ser2
2 6
3 7
4 8
dtype: int64
uniques = pd.Series(np.union1d(unique_ser1,unique_ser2))
uniques
0 1
1 2
2 3
3 6
4 7
5 8
dtype: int64
At last, we merge the two series unique_ser1 and unique_ser2 using the NumPy function union1d and cast the array into a series.
2nd Method
series_u = pd.Series(np.union1d(ser1,ser2))
series_i = pd.Series(np.intersect1d(ser1,ser2))
series_u[~series_u.isin(series_i)]
0 1
1 2
2 3
5 6
6 7
7 8
dtype: int64
The second method is quite similar to the first one, the difference is that this time we get first the intersection and the union separately using NumPy function and then use indexing on the union series to get the unique element in the two series just like we did in exercise 6.
Ex 8: How to get the minimum, 25th percentile, median, 75th, and max of a numeric series?
Q: Compute the minimum, 25th percentile, median, 75th, and maximum of ser.
ser = pd.Series(np.random.normal(10, 5, 25))
Desired output
#the minimum is :1.63, the 25th percentile is: 7.27, the median is: 10.21, the 75th percentile is: 15.29 and the maximum is: 22.64
Solution
1st Method
print("the minimum is :{0:.2f}, the 25th percentile is: {1:.2f}, the median is: {2:.2f}, the 75th percentile is: {3:.2f} and the maximum is: {4:.2f}".format(ser.min(),ser.quantile(q=0.25),ser.median(),ser.quantile(q=0.75),ser.max()))
the minimum is :1.63, the 25th percentile is: 7.27, the median is: 10.21, the 75th percentile is: 15.29 and the maximum is: 22.64
2nd Method
print("the minimum is :{0:.2f}, the 25th percentile is: {1:.2f}, the median is: {2:.2f}, the 75th percentile is: {3:.2f} and the maximum is: {4:.2f}".format(ser.quantile(q=0),ser.quantile(q=0.25),ser.quantile(q=0.50),ser.quantile(q=0.75),ser.quantile(q=1)))
the minimum is :1.63, the 25th percentile is: 7.27, the median is: 10.21, the 75th percentile is: 15.29 and the maximum is: 22.64
We can get the different percentile using the quantile method and pass as argument q the percentile, so for the 0th percentile (which is the min) q will be 0, for the 25th percentile q will be 0.25, for the 50th percentile (which is the median) q will be 0.5, for the 75th percentile q will be 0.75 and last for the 100th percentile (which is the max) q will be 1.
The min, median and max have their functions too in case you don’t wanna use the quantile function.
Ex 9: How to get frequency counts of unique items of a series?
Q: Calculate the frequency counts of each unique value ser.
ser = pd.Series(np.take(list('abcdefgh'), np.random.randint(8, size=30)))
Desired output
# b 7
# a 5
# e 5
# f 4
# d 4
# c 2
# h 2
# g 1
# dtype: int64
Solution
ser.value_counts()
b 7
a 5
e 5
f 4
d 4
c 2
h 2
g 1
dtype: int64
To get the count of how many times a value is repeated, we use the value_count function on the series.
Ex 10: How to keep only the top 2 most frequent values as it is and replace everything else as ‘Other’?
Q: From ser, keep the top 2 most frequent items as it is and replace everything else as ‘Other’.
np.random.RandomState(100)
ser = pd.Series(np.random.randint(1, 5, [12]))
Desired output
# 0 2
# 1 4
# 2 2
# 3 other
# 4 2
# 5 4
# 6 other
# 7 2
# 8 2
# 9 other
# 10 other
# 11 4
# dtype: object
Solution
most_freq_el = ser.value_counts()[:2].index
ser[~ser.isin(most_freq_el)] = "other"
ser
0 2
1 4
2 2
3 other
4 2
5 4
6 other
7 2
8 2
9 other
10 other
11 4
dtype: object
We get first the two most frequent element in ser using the value_count, which will return the series with the values as indexes and the count of how many times those values are repeated. We only need the value so we called the index function.
We use isin and indexing to select all the values other than the two most frequent value and assign it to the string “other”.
Ex 11: How to bin a numeric series to 10 groups of equal size?
Q: Bin the series ser into 10 equal deciles and replace the values with the bin name.
ser = pd.Series(np.random.random(20))
Desired output
# 0 4th
# 1 9th
# 2 6th
# 3 2nd
# 4 2nd
# dtype: category
# Categories (10, object): [1st < 2nd < 3rd < 4th ... 7th < 8th < 9th < 10th]
Solution
pd.cut(ser,bins=10,labels=["1st","2nd","3rd","4th","5th","6th","7th","8th","9th","10th"]).head()
0 4th
1 9th
2 6th
3 2nd
4 2nd
dtype: category
Categories (10, object): [1st < 2nd < 3rd < 4th ... 7th < 8th < 9th < 10th]
To get the segment of the series, we use the cut function pass the series, specify how many bins or basket we want to use and give them a label.
Ex 12: How to convert a numpy array to a dataframe of given shape? (L1)
Q: Reshape the series ser into a dataframe with 7 rows and 5 columns
ser = pd.Series(np.random.randint(1, 10, 35))
Desired output
# array([[9, 1, 4, 8, 3],
# [2, 3, 9, 7, 2],
# [2, 9, 6, 6, 5],
# [2, 2, 7, 8, 5],
# [7, 3, 3, 9, 6],
# [2, 3, 4, 3, 3],
# [1, 6, 6, 3, 1]])
Solution
1st Method
ser.values.reshape((7,5))
array([[9, 1, 4, 8, 3],
[2, 3, 9, 7, 2],
[2, 9, 6, 6, 5],
[2, 2, 7, 8, 5],
[7, 3, 3, 9, 6],
[2, 3, 4, 3, 3],
[1, 6, 6, 3, 1]])
To reshape the ser, we call the reshape function on the series and pass a tuple with the first element the number of rows and the second element the number of columns.
2nd Method
ser.values.reshape((-1,5))
array([[9, 1, 4, 8, 3],
[2, 3, 9, 7, 2],
[2, 9, 6, 6, 5],
[2, 2, 7, 8, 5],
[7, 3, 3, 9, 6],
[2, 3, 4, 3, 3],
[1, 6, 6, 3, 1]])
ser.values.reshape((7,-1))
array([[9, 1, 4, 8, 3],
[2, 3, 9, 7, 2],
[2, 9, 6, 6, 5],
[2, 2, 7, 8, 5],
[7, 3, 3, 9, 6],
[2, 3, 4, 3, 3],
[1, 6, 6, 3, 1]])
The other way to go about this would be to populate the tuple with only one element (row or column) and let Pandas figure out the other element to be used by placing -1 in the tuple.
Ex 13: How to find the positions of numbers that are multiples of 3 from a series?
Q: Find the positions of numbers that are multiples of 3 from ser.
ser = pd.Series(np.random.randint(1, 10, 7))
Desired output
# 0 1
# 1 6
# dtype: int64
Solution
1st Method
pd.Series(ser[ser%3 == 0].index)
0 1
1 6
dtype: int64
We index the series and pass in the condition to return all the values that have a remainder of 0 when divided by 3. It means that those values are multiples of 3.
We then extract the indexes(positions) and cast them to a series.
2nd Method
pd.Series(np.argwhere(ser%3==0).flatten())
0 1
1 6
dtype: int64
Alternately, we could use NumPy function argwhere which returns all the values that have a remainder of 0 when divided by 3. We then flatten the array and cast it to a series.
Ex 14: How to extract items at given positions from a series
Q: From ser, extract the items at positions in list pos.
ser = pd.Series(list('abcdefghijklmnopqrstuvwxyz'))
pos = [0, 4, 8, 14, 20]
Desired output
# 0 a
# 4 e
# 8 i
# 14 o
# 20 u
# dtype: object
Solution
1st Method
pd.Series(ser.iloc[pos])
0 a
4 e
8 i
14 o
20 u
dtype: object
We use the iloc function to get the element at a specific index and cast to a series.
2nd Method
ser.take(pos)
0 a
4 e
8 i
14 o
20 u
dtype: object
Alternatively, we can use the take function to achieve the same result.
Ex 15: How to stack two series vertically?
Q: Stack ser1 and ser2 vertically to form a dataframe.
ser1 = pd.Series(range(5))
ser2 = pd.Series(list('abcde'))
Desired output
# 0 0
# 1 1
# 2 2
# 3 3
# 4 4
# 0 a
# 1 b
# 2 c
# 3 d
# 4 e
# dtype: object
Solution
pd.concat((ser1,ser2),axis=0)
0 0
1 1
2 2
3 3
4 4
0 a
1 b
2 c
3 d
4 e
dtype: object
To combine the two series into one, we use the concat function and pass in as a tuple the two series and set the axis to 0 to tell Pandas that we want to concatenate row-wise(vertically).
Ex 16: How to get the positions of items of series A in another series B?
Q: Get the positions of items of ser2 in ser1 as a list.
ser1 = pd.Series([10, 9, 6, 5, 3, 1, 12, 8, 13])
ser2 = pd.Series([1, 3, 10, 13])
Desired output
# [0, 4, 5, 8]
Solution
list(ser1[ser1.isin(ser2)].index)
[0, 4, 5, 8]
We use the isin function on ser1 in ser2. We get back the indexes that correspond to the positions and cast them to a list.
Ex 17: How to compute the mean squared error on series A and predicted series B?
Q: Compute the mean squared error of truth and pred series.
truth = pd.Series(range(10))
pred = pd.Series(range(10)) + np.random.random(10)
Desired output
# Since we are generating random variable, your result will be different
#0.34688071383011976
Solution
np.square(np.subtract(truth,pred)).mean()
0.34688071383011976
np.mean((truth-pred)**2)
0.34688071383011976
The two notation is the same, to find the mean squared error we use its formula which pretty much translates into the code above.
Visit the Wikipedia page to learn more about the mean squared error.
Ex 18: How to convert the first character of each element in a series to uppercase?
Q: Change the first character of each word to upper case in each word of ser.
ser = pd.Series(['how', 'to', 'kick', 'ass?'])
Desired output
# 0 How
# 1 To
# 2 Kick
# 3 Ass?
# dtype: object
Solution
1st Method: The pythonic way (least recommended)
def uppercase(the_series):
capitalized_ser = []
for word in the_series:
capitalized_ser.append(word.capitalize())
print(pd.Series(capitalized_ser))
uppercase(ser)
0 How
1 To
2 Kick
3 Ass?
dtype: object
One way to solve this would be to use the vanilla Python code. We build a function that takes the series and create a new list to store the words that we will be capitalizing. We loop through the series and capitalize each word and place it in the list. We finally cast the list to a series and print it.
The reason why this is the least recommended of the bunch, it is because to achieve the result by writing five lines of code which make our code verbose.
2nd Method: Using May (recommended)
ser.map(lambda x: x.title())
0 How
1 To
2 Kick
3 Ass?
dtype: object
Ban! a much simpler method in one line of code, is to use map with lambda expression. we use the title function to capitalize each first letter of each word. We can use the capitalize function instead of the title function.
3rd Method: Using Pandas built-in function (most recommended)
ser.str.capitalize()
0 How
1 To
2 Kick
3 Ass?
dtype: object
We can call the pandas’s capitalize function write away series’string.
Ex 19: How to calculate the number of characters in each word in a series?
Q: Get the number of characters in each word in a series
ser = pd.Series(['how', 'to', 'kick', 'ass?'])
Desired output
# 0 3
# 1 2
# 2 4
# 3 4
# dtype: int64
Solution
1st Method
ser.str.count(pat=".")
0 3
1 2
2 4
3 4
dtype: int64
We can get the length of each word in the series by calling the string and the count function. We pass in the count function the pattern “.” (it is a regular expression) to select any character in the word.
2nd Method
ser.map(lambda x: len(x))
0 3
1 2
2 4
3 4
dtype: int64
We can also use map with lambda expression by getting the length of each word by using len(x).
Ex 20: How to compute the difference of differences between consecutive numbers of a series?
Q: Find the difference of differences between the consecutive numbers of ser.
ser = pd.Series([1, 3, 6, 10, 15, 21, 27, 35])
Desired output
# [nan, 2.0, 3.0, 4.0, 5.0, 6.0, 6.0, 8.0]
# [nan, nan, 1.0, 1.0, 1.0, 1.0, 0.0, 2.0]
Solution
ser.diff().tolist()
[nan, 2.0, 3.0, 4.0, 5.0, 6.0, 6.0, 8.0]
ser.diff().diff().tolist()
[nan, nan, 1.0, 1.0, 1.0, 1.0, 0.0, 2.0]
To calculate the difference of a series element compared with another element in the series, we use the diff function.
The first line of code we use it on the element in the series and the second time we use it on the difference list. So we have performed a difference of difference on that series.
Ex 21: How to convert a series of date-strings to a timeseries?
Q: How to convert a series of date-strings to a timeseries?
ser = pd.Series(['01 Jan 2010', '02-02-2011', '20120303', '2013/04/04', '2014-05-05', '2015-06-06T12:20'])
Desired output
# 0 2010-01-01 00:00:00
# 1 2011-02-02 00:00:00
# 2 2012-03-03 00:00:00
# 3 2013-04-04 00:00:00
# 4 2014-05-05 00:00:00
# 5 2015-06-06 12:20:00
# dtype: datetime64[ns]
Solution
pd.to_datetime(ser)
0 2010-01-01 00:00:00
1 2011-02-02 00:00:00
2 2012-03-03 00:00:00
3 2013-04-04 00:00:00
4 2014-05-05 00:00:00
5 2015-06-06 12:20:00
dtype: datetime64[ns]
To get the timeseries of the corresponding series, we use the function to_datetime and pass the series as the argument.
Ex 22: How to get the day of the month, week number, day of year and day of the week from a series of date strings?
Q: Get the day of the month, week number, day of year and day of the week from ser.
ser = pd.Series(['01 Jan 2010', '02-02-2011', '20120303', '2013/04/04', '2014-05-05', '2015-06-06T12:20'])
Desired output
# Date: [1, 2, 3, 4, 5, 6]
# Week number: [53, 5, 9, 14, 19, 23]
# Day num of year: [1, 33, 63, 94, 125, 157]
# Day of week: ['Friday', 'Wednesday', 'Saturday', 'Thursday', 'Monday', 'Saturday']
Solution
ser_dt = pd.to_datetime(ser)
date = list(ser_dt.dt.day)
week_number = list(ser_dt.dt.week)
day_num = list(ser_dt.dt.dayofyear)
day_name = list(ser_dt.dt.day_name())
print("Date: {}\nWeek number: {}\nDay num of year: {}\nDay of week: {}".format(date,week_number,day_num,day_name))
Date: [1, 2, 3, 4, 5, 6]
Week number: [53, 5, 9, 14, 19, 23]
Day num of year: [1, 33, 63, 94, 125, 157]
Day of week: ['Friday', 'Wednesday', 'Saturday', 'Thursday', 'Monday', 'Saturday']
We start by changing the series into a datetime, then access its dt function to get the dates, week number, day of the year and day name. Finally, we cast them to a list and print those variables.
Ex 23: How to convert year-month string to dates corresponding to the 4th day of the month?
Q: Change ser to dates that start with 4th of the respective months.
ser = pd.Series(['Jan 2010', 'Feb 2011', 'Mar 2012'])
Desired output
# 0 2010-01-04
# 1 2011-02-04
# 2 2012-03-04
# dtype: datetime64[ns]
Solution
from dateutil.parser import parse
ser.map(lambda d: parse(d+" 4"))
0 2010-01-04
1 2011-02-04
2 2012-03-04
dtype: datetime64[ns]
For this exercise, we will need to install the parse function from the dateutile package to parse most known formats representing a date and/or time.
Then we will use the map function with a lambda expression, and parse the series concatenated with the date we want to add to the series.
Ex 24: How to filter words that contain atleast 2 vowels from a series?
Q: From ser, extract words that contain atleast 2 vowels.
ser = pd.Series(['Apple', 'Orange', 'Plan', 'Python', 'Money'])
Desired output
# 0 Apple
# 1 Orange
# 4 Money
# dtype: object
Solution
vowel_count = ser.str.count(pat="(?i)[aeiou]")
vowel_count
0 2
1 3
2 1
3 1
4 2
dtype: int64
ser[np.argwhere(vowel_count.values >= 2).flatten()]
0 Apple
1 Orange
4 Money
dtype: object
We use the count function to get the count of vowels in each word by using a regular expression pattern. We get back a series with positions and the corresponding count of vowel at those positions.
We use the Numpy argwhere function to return the indexes where the condition in the paratheses is satisfied. In this example, the condition is a vowel count greater than 2. we get back 3 arrays of the indexes where the word has 2 or more vowels and then we flatten the 3 arrays into one 1D array. We use indexing to get back the words from the original series.
Ex 25: How to filter valid emails from a series?
Extract the valid emails from the series emails. The regex pattern for valid emails is provided as reference.
emails = pd.Series(['buying books at amazom.com', 'rameses@egypt.com', 'matt@t.co', 'narendra@modi.com','dad@comp'])
pattern ='[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\\.[A-Za-z]{2,4}'
Desired output
# 1 rameses@egypt.com
# 2 matt@t.co
# 3 narendra@modi.com
# dtype: object
Solution
emails[emails.str.match(pat=pattern)]
1 rameses@egypt.com
2 matt@t.co
3 narendra@modi.com
dtype: object
This exercise is similar to the previous one. This time, we use the match function to get back all the words that match the pattern and use the indexing to get those words.
Conclusion
Pandas is such a wonderful library that is why it is my favorite libraries. It is easy to grasp, and there are a plethora of resources online if you are stuck. Do not forget to visit StackOverflow too, and ask questions. There is always someone ready to help.
This post is exclusively focused on series, the primary data structure of Pandas. In the next two posts, we will explore the dataframe which is the most popular Pandas data structure. Find the jupyter notebook version of this post on my GitHub profile here.
Thank you again for doing these exercises with me. I hope you have learned one or two things. If you like this post, please subscribe to stay updated with new posts, and if you have a thought or a question, I would love to hear it by commenting below. Cheers, and keep learning!