
As a refresh from my previous blog, deep learning is a subset of machine learning which learns by using layers of neurons like the ones found in our brain to output an expected result. The layers are organized in a way that can break down the input into different layers of abstraction. The more the layers we have, the deeper the neural network.
 picture credit: medium
picture credit: medium
Quick example
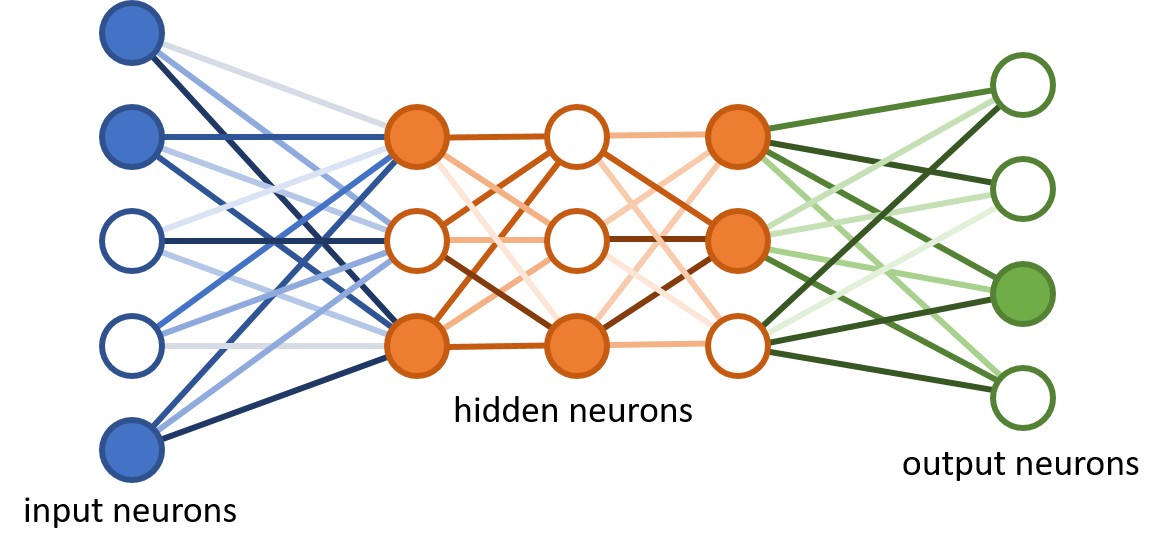
Let take an oversimplified example, let’s say that this neural net above is supposed to tell which number (0-9) is a character input (the nodes in blue) while it has been trained, it has an idea on how the number 0 to 9 looks like (the node in green). So it has to match the input and the output.
Let’s say we give it a 2. The character two will be divided into many small pieces of the character 2 in either straight or curved lines. These lines will be passed to the hidden layer (the orange nodes). The nodes at this layer will analyze them depending on whether these are straight or curved, they will be passed on to the next layer in the hidden section, this layer on its turn will analyze and check if there is a collection of intersections or curves between the lines from the previous layer. The more we add the layer, the more new connections are formed and that the end of the hidden layers, it can guess approximately using % which number it is because of the patterns received.
why now?
Now let’s answer the pertinent question. Why has deep learning gain popularity in recent past years? Indeed from 2010, deep learning has been massively used in the tech community as well as in other sectors. Even though this is true, artificial intelligence was not invented yesterday, nor last week. Surprisingly, it has been around since the 50’s early 60’s, but from then it has evolved steadily in the ’70s. They were self-driving cars in the ’80s. Don’t believe me? watch this video. Something worth mentioning is that by then AI with its sub-field was a very young academic subject and was mostly studied at the ivy league university.
 picture credit: medium
picture credit: medium
So what happened? You may ask, well two important factors happened — processing power and data.
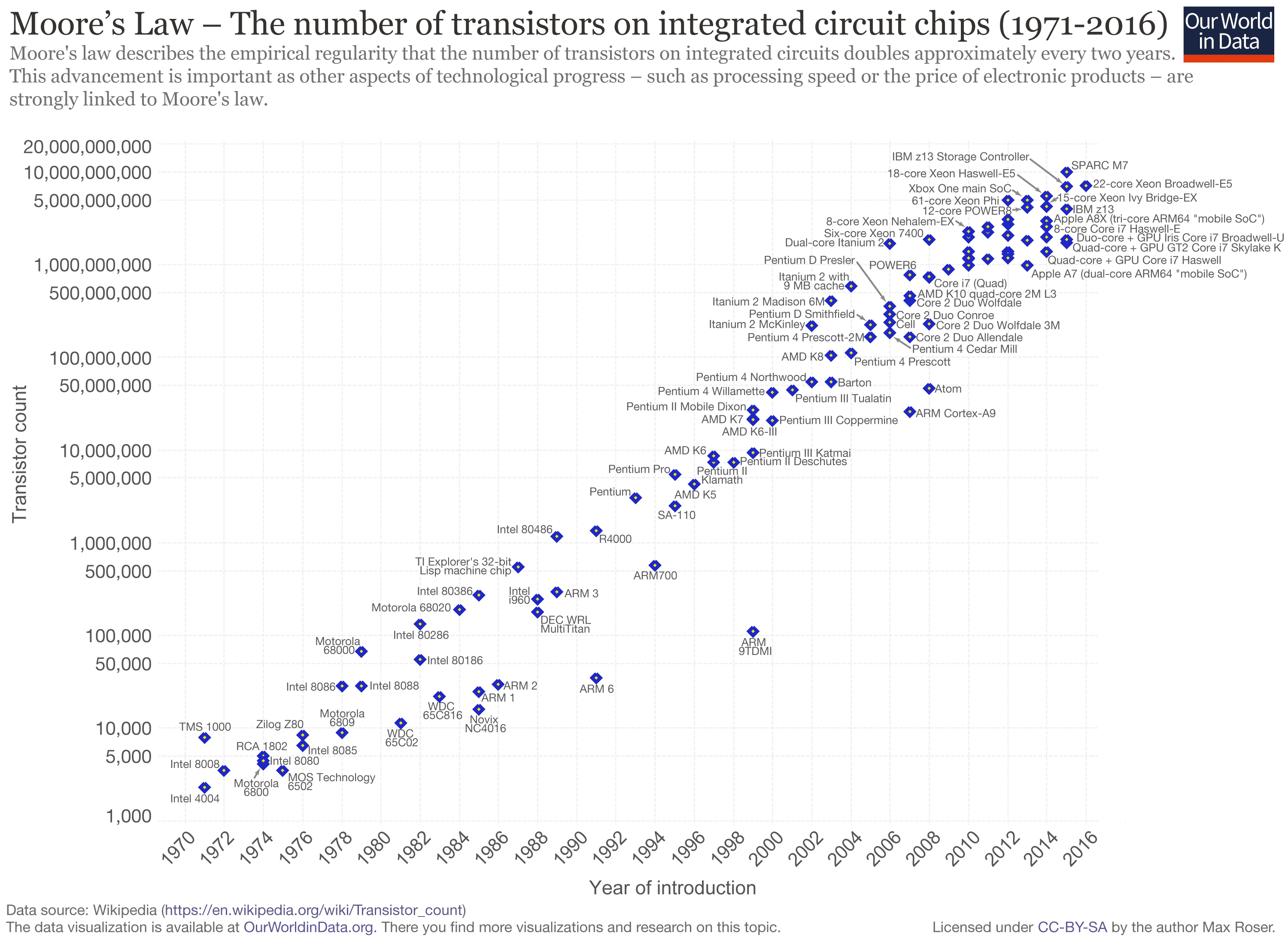
Since the launch of the Intel 4004 in 1971 which was composed of 2300 transistors capable of executing between 46,250 to 92,500 instructions per second(which was groundbreaking at the time), fast forward to these days with the Intel i9 capable of performing 80 billions instructions per second which translate to a 900 times increase in processing power. This increase in the power of computers has also made machines less power-hungry and very affordable to the mass population and universities which invest a lot in computers labs. Another notable mention is the Qualcomm’s Snapdragon 8cx new 7nm processor (processors found so far only in smartphones) said to be able to power a PC. If I had been told this two years ago, I would not have believed it. This shows you how the processing power has gone from the early days of a computer filling a whole room up to now, whereas it can be carried in a pocket. But as of anything, this trend will not continue forever, and we are reaching the plateau of the microprocessor’s innovation.
Moore’s law
 picture credit: wikipedia
picture credit: wikipedia
Since the introduction of the world wide web in 1994, the amount of data on the web, which proportionally correlated to the number of internet users (bots and humans), has skyrocketed. More people, especially from developing countries, are discovering the internet dues to a decrease in the price of smartphones and internet bundles. There is more and more tweets, shares, and clicks on the web each year. Adding to this, online retailers services, schools to hospitals need to store data from their customers.
“Data is the new oil.”
 picture credit: visualcapitalist
picture credit: visualcapitalist
the 3 VS
With more data generated, this eventually leads to the exponential creation of data, this type of data is called Big Data and is characterized by 3 Vs. Which are:
- Volume
- Velocity
- Variety
Start with its volume. Big data needs to be analyzed with specialized tools like Hive, Spark, or Hadoop because traditional database technologies like SQL or NoSQL won’t be able to handle its magnitude efficiently. Velocity, which is the amount of data that flows in and out a database per second. For example, a company like Facebook has to deal with a large quantity of data each second from its users who are streaming or liking a video. Finally, when it comes to the variety, we can see a rapid change in the type of data found on the internet. Contrary to the early days where we mostly found texts linked together, now we find a variety of data file format from PDF, photos, videos, audio, location data, etc.
Conclusion
The perfect marriage between big data and the increased processing power has allowed the training of complex algorithms on super-computers, thus leading to an increased usage of deep learning since 2010. Some exciting advancement in technology has been enabled by deep learning like changing a low-resolution image to a high definition using GANs (Generative adversarial network)(YouTube video here) or this website that let you create your vocal avatar using celebrities’ voices like Trump. Another one called “everybody can dance now” (YouTube video here) uses a video from a professional dancer and apply to another video where there is a person who does not dance. After the training on those two videos, the person on the second video now bounces like a pro. Very cool!
We can’t deny that deep learning has a bright future ahead, but also we should be concerned about its drawbacks like fake news.
Thank you for reading this tutorial. I hope you have learned one or two things. If you like this post, please subscribe to stay updated with new posts, and if you have a thought or a question, I would love to hear it by commenting below.